
Les plans de site d’actualités utilisent des protocoles de plan de site différents et uniques pour fournir plus d’informations aux moteurs de recherche d’actualités.
Un plan du site des actualités contient les actualités publiées au cours des dernières 48 heures.

Les balises du plan du site d’actualités incluent le titre, la langue, le nom, le genre, la date de publication, les mots-clés et même les symboles boursiers de la publication d’actualités.
Comment pouvez-vous utiliser ces sitemaps à votre avantage pour la recherche de contenu et l’analyse concurrentielle ?
Dans ce didacticiel Python, vous apprendrez un processus en 10 étapes pour analyser les sitemaps d’actualités et visualiser les tendances thématiques qui y sont découvertes.
Notes d’entretien ménager pour nous aider à démarrer
Ce tutoriel a été écrit lors de l’invasion de l’Ukraine par la Russie.
En utilisant l’apprentissage automatique, nous pouvons même étiqueter les sources d’information et les articles en fonction de la source d’information « objective » et de la source d’information « sarcastique ».
Mais pour garder les choses simples, nous nous concentrerons sur des sujets avec analyse de fréquence.
Nous utiliserons plus de 10 sources d’information mondiales aux États-Unis et au Royaume-Uni
Remarque : Nous aimerions inclure les sources d’actualités russes, mais elles ne disposent pas d’un sitemap d’actualités approprié. Même s’ils l’avaient fait, ils bloquent les demandes externes.
Comparer l’occurrence du mot de “invasion” et “libération” provenant de sources d’information occidentales et orientales montre l’avantage des méthodes d’analyse de texte de fréquence de distribution.
Ce dont vous avez besoin pour analyser le contenu des actualités avec Python
Les bibliothèques Python associées pour l’audit d’un sitemap d’actualités afin de comprendre la stratégie de contenu de la source d’actualités sont répertoriées ci-dessous :
- Outils publicitaires.
- Pandas.
- Plotly Express, sous-parcelles et objets graphiques.
- Re (Regex).
- Corde.
- NLTK (Corpus, Mots vides, Ngrams).
- Données Unicode.
- Matplotlib.
- Compréhension de base de la syntaxe Python.
10 étapes pour l’analyse du sitemap des actualités avec Python
Tout est configuré ? Allons-y.
1. Prenez les URL des actualités du plan du site des actualités
Nous avons choisi “The Guardian”, “New York Times”, “Washington Post”, “Daily Mail”, “Sky News”, “BBC” et “CNN” pour examiner les URL d’actualités des sitemaps d’actualités.
df_guardian = adv.sitemap_to_df("http://www.theguardian.com/sitemaps/news.xml")
df_nyt = adv.sitemap_to_df("https://www.nytimes.com/sitemaps/new/news.xml.gz")
df_wp = adv.sitemap_to_df("https://www.washingtonpost.com/arcio/news-sitemap/")
df_bbc = adv.sitemap_to_df("https://www.bbc.com/sitemaps/https-index-com-news.xml")
df_dailymail = adv.sitemap_to_df("https://www.dailymail.co.uk/google-news-sitemap.xml")
df_skynews = adv.sitemap_to_df("https://news.sky.com/sitemap-index.xml")
df_cnn = adv.sitemap_to_df("https://edition.cnn.com/sitemaps/cnn/news.xml")
2. Examinez un exemple de sitemap d’actualités avec Python
J’ai utilisé la BBC comme exemple pour démontrer ce que nous venons d’extraire de ces plans de site d’actualités.
df_bbc
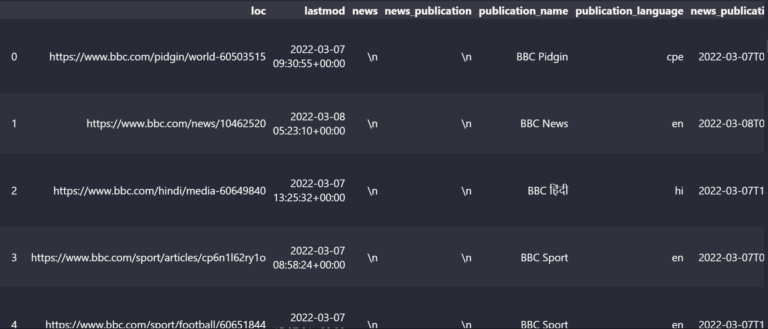 Vue du cadre de données du plan du site
Vue du cadre de données du plan du siteLe plan du site de la BBC contient les colonnes ci-dessous.
df_bbc.columns
 Balises de sitemap en tant que colonnes de bloc de données
Balises de sitemap en tant que colonnes de bloc de donnéesLes structures de données générales de ces colonnes sont ci-dessous.
df_bbc.info()
 Colonnes et types de données du sitemap
Colonnes et types de données du sitemapLa BBC n’utilise pas la colonne “news_publication” et autres.
3. Trouvez les mots les plus utilisés dans les URL des publications d’actualités
Pour voir les mots les plus utilisés dans les URL des sites d’actualités, nous devons utiliser les méthodes « str », « explode » et « split ».
df_dailymail["loc"].str.split("/").str[5].str.split("-").explode().value_counts().to_frame()
loc |
|
|---|---|
article |
176 |
Russian |
50 |
Ukraine |
50 |
says |
38 |
reveals |
38 |
... |
... |
readers |
1 |
Red |
1 |
Cross |
1 |
provide |
1 |
weekend.html |
1 |
5445 rows × 1 column
On voit que pour le « Daily Mail », « la Russie et l’Ukraine » sont le sujet principal.
4. Trouvez la langue la plus utilisée dans les publications d’actualités
La structure de l’URL ou la section “langue” de la publication d’actualités peut être utilisée pour voir les langues les plus utilisées dans les publications d’actualités.
Dans cet échantillon, nous avons utilisé “BBC” pour voir leur priorité linguistique.
df_bbc["publication_language"].head(20).value_counts().to_frame()
| publication_language | |
en |
698 |
fa |
52 |
sr |
52 |
ar |
47 |
mr |
43 |
hi |
43 |
gu |
41 |
ur |
35 |
pt |
33 |
te |
31 |
ta |
31 |
cy |
30 |
ha |
29 |
tr |
28 |
es |
25 |
sw |
22 |
cpe |
22 |
ne |
21 |
pa |
21 |
yo |
20 |
20 rows × 1 column
Pour atteindre la population russe via Google Actualités, toutes les sources d’informations occidentales doivent utiliser la langue russe.
Certaines institutions de presse internationales ont commencé à adopter cette perspective.
Si vous êtes un référenceur d’actualités, il est utile de regarder les publications en langue russe de vos concurrents pour diffuser des informations objectives en Russie et être compétitif au sein de l’industrie de l’information.
5. Vérifiez les titres d’actualités pour la fréquence des mots
Nous avons utilisé la BBC pour voir les “titres d’actualités” et quels mots sont les plus fréquents.
df_bbc["news_title"].str.split(" ").explode().value_counts().to_frame()
news_title |
|
|---|---|
to |
232 |
in |
181 |
- |
141 |
of |
140 |
for |
138 |
... |
... |
ፊልም |
1 |
ብላክ |
1 |
ባንኪ |
1 |
ጕሒላ |
1 |
niile |
1 |
11916 rows × 1 columns
Le problème ici est que nous avons « tous les types de mots dans les titres des actualités », tels que les « mots vides sans contexte ».
Nous devons nettoyer ces types de termes non catégoriques pour mieux comprendre leur objectif.
from nltk.corpus import stopwords
stop = stopwords.words('english')
df_bbc_news_title_most_used_words = df_bbc["news_title"].str.split(" ").explode().value_counts().to_frame()
pat = r'b(?:{})b'.format('|'.join(stop))
df_bbc_news_title_most_used_words.reset_index(drop=True, inplace=True)
df_bbc_news_title_most_used_words["without_stop_words"] = df_bbc_news_title_most_used_words["words"].str.replace(pat,"")
df_bbc_news_title_most_used_words.drop(df_bbc_news_title_most_used_words.loc[df_bbc_news_title_most_used_words["without_stop_words"]==""].index, inplace=True)
df_bbc_news_title_most_used_words
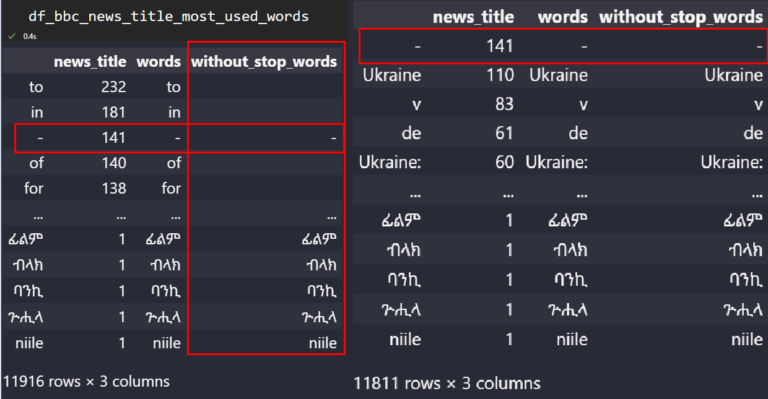 La colonne « without_stop_words » implique les valeurs de texte nettoyées.
La colonne « without_stop_words » implique les valeurs de texte nettoyées.Nous avons supprimé la plupart des mots vides à l’aide de la méthode “regex” et “replace” de Pandas.
La deuxième préoccupation est de supprimer les “ponctuations”.
Pour cela, nous allons utiliser le module « string » de Python.
import string
df_bbc_news_title_most_used_words["without_stop_word_and_punctation"] = df_bbc_news_title_most_used_words['without_stop_words'].str.replace('[{}]'.format(string.punctuation), '')
df_bbc_news_title_most_used_words.drop(df_bbc_news_title_most_used_words.loc[df_bbc_news_title_most_used_words["without_stop_word_and_punctation"]==""].index, inplace=True)
df_bbc_news_title_most_used_words.drop(["without_stop_words", "words"], axis=1, inplace=True)
df_bbc_news_title_most_used_words
news_title |
without_stop_word_and_punctation |
|
|---|---|---|
Ukraine |
110 |
Ukraine |
v |
83 |
v |
de |
61 |
de |
Ukraine: |
60 |
Ukraine |
da |
51 |
da |
... |
... |
... |
ፊልም |
1 |
ፊልም |
ብላክ |
1 |
ብላክ |
ባንኪ |
1 |
ባንኪ |
ጕሒላ |
1 |
ጕሒላ |
niile |
1 |
niile |
11767 rows × 2 columns
Ou, utilisez “df_bbc_news_title_most_used_words[“news_title”].to_frame() » pour prendre une image plus claire des données.
news_title |
|
|---|---|
Ukraine |
110 |
v |
83 |
de |
61 |
Ukraine: |
60 |
da |
51 |
... |
... |
ፊልም |
1 |
ብላክ |
1 |
ባንኪ |
1 |
ጕሒላ |
1 |
niile |
1 |
11767 rows × 1 columns
Nous voyons 11 767 mots uniques dans les URL de la BBC, et l’Ukraine est le plus populaire, avec 110 occurrences.
Il existe différentes phrases liées à l’Ukraine dans le bloc de données, telles que “Ukraine :.”
Le “NLTK Tokenize” peut être utilisé pour unir ces types de variations différentes.
La section suivante utilisera une méthode différente pour les unir.
Remarque : Si vous voulez faciliter les choses, utilisez Adtools comme ci-dessous.
adv.word_frequency(df_bbc["news_title"],phrase_len=2, rm_words=adv.stopwords.keys())
Le résultat est ci-dessous.
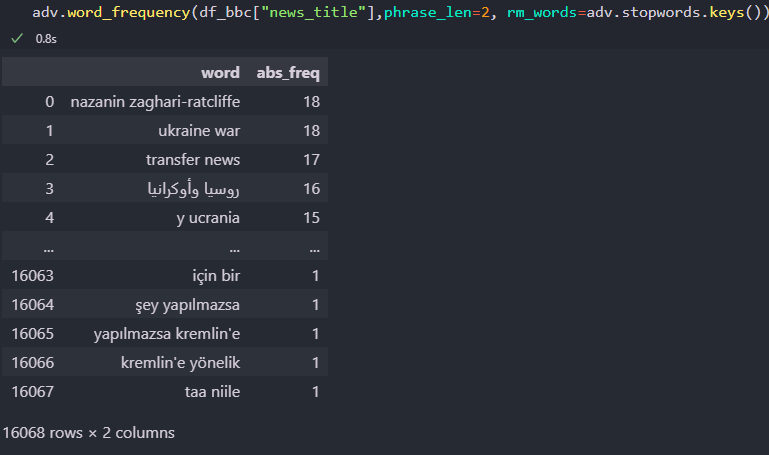 Analyse de texte avec Adtools
Analyse de texte avec Adtools“adv.word_frequency” a les attributs “phrase_len” et “rm_words” pour déterminer la longueur de l’occurrence de la phrase et supprimer les mots vides.
Vous pouvez me dire, pourquoi ne l’ai-je pas utilisé en premier lieu ?
Je voulais vous montrer un exemple pédagogique avec “regex, NLTK et la chaîne” afin que vous puissiez comprendre ce qui se passe dans les coulisses.
6. Visualisez les mots les plus utilisés dans les titres d’actualités
Pour visualiser les mots les plus utilisés dans les titres d’actualités, vous pouvez utiliser le bloc de code ci-dessous.
df_bbc_news_title_most_used_words["news_title"] = df_bbc_news_title_most_used_words["news_title"].astype(int) df_bbc_news_title_most_used_words["without_stop_word_and_punctation"] = df_bbc_news_title_most_used_words["without_stop_word_and_punctation"].astype(str) df_bbc_news_title_most_used_words.index = df_bbc_news_title_most_used_words["without_stop_word_and_punctation"] df_bbc_news_title_most_used_words["news_title"].head(20).plot(title="The Most Used Words in BBC News Titles")
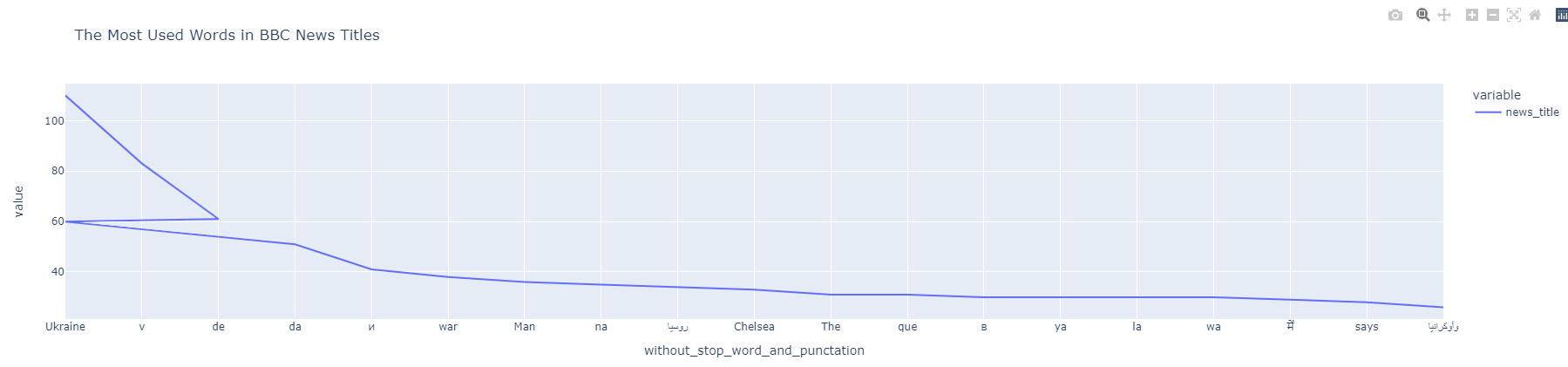 Visualisation des NGrams
Visualisation des NGramsVous vous rendez compte qu’il y a une “ligne brisée”.
Vous souvenez-vous de « Ukraine » et « Ukraine : » dans le bloc de données ?
Lorsque nous supprimons la « ponctuation », les deuxième et première valeurs deviennent identiques.
C’est pourquoi le graphique linéaire indique que l’Ukraine est apparue 60 fois et 110 fois séparément.
Pour éviter une telle divergence de données, utilisez le bloc de code ci-dessous.
df_bbc_news_title_most_used_words_1 = df_bbc_news_title_most_used_words.drop_duplicates().groupby('without_stop_word_and_punctation', sort=False, as_index=True).sum()
df_bbc_news_title_most_used_words_1
news_title |
|
|---|---|
without_stop_word_and_punctation |
|
Ukraine |
175 |
v |
83 |
de |
61 |
da |
51 |
и |
41 |
... |
... |
ፊልም |
1 |
ብላክ |
1 |
ባንኪ |
1 |
ጕሒላ |
1 |
niile |
1 |
11109 rows × 1 columns
Les lignes dupliquées sont supprimées et leurs valeurs sont additionnées.
Maintenant, visualisons-le à nouveau.
7. Extrayez les N-Grams les plus populaires des titres d’actualités
Extraire des n-grammes des titres d’actualités ou normaliser les mots de l’URL et former des n-grammes pour comprendre l’actualité globale est utile pour comprendre quelle publication d’actualités aborde quel sujet. Voici comment.
import nltk import unicodedata import re def text_clean(content):
lemmetizer = nltk.stem.WordNetLemmatizer()
stopwords = nltk.corpus.stopwords.words('english')
content = (unicodedata.normalize('NFKD', content)
.encode('ascii', 'ignore')
.decode('utf-8', 'ignore')
.lower())
words = re.sub(r'[^ws]', '', content).split()
return [lemmetizer.lemmatize(word) for word in words if word not in stopwords]
raw_words = text_clean(''.join(str(df_bbc['news_title'].tolist())))
raw_words[:10]
OUTPUT>>> ['oneminute', 'world', 'news', 'best', 'generation', 'make', 'agyarkos', 'dream', 'fight', 'card']
La sortie montre que nous avons “lemmatisé” tous les mots dans les titres des nouvelles et les avons mis dans une liste.
La compréhension de la liste fournit un raccourci rapide pour filtrer facilement chaque mot vide.
L’utilisation de “nltk.corpus.stopwords.words (“english”)” fournit tous les mots vides en anglais.
Mais vous pouvez ajouter des mots vides supplémentaires à la liste pour étendre l’exclusion de mots.
Le “unicodedata” est de canoniser les caractères.
Les caractères que nous voyons sont en fait des octets Unicode comme “U + 2160 ROMAN NUMERAL ONE” et le caractère romain “U + 0049 LATIN CAPITAL LETTER I” sont en fait les mêmes.
Le “unicodedata.normalize” distingue les différences de caractères afin que le lemmatiseur puisse différencier les différents mots avec des caractères similaires les uns des autres.
pd.set_option("display.max_colwidth",90)
bbc_bigrams = (pd.Series(ngrams(words, n = 2)).value_counts())[:15].sort_values(ascending=False).to_frame()
bbc_trigrams = (pd.Series(ngrams(words, n = 3)).value_counts())[:15].sort_values(ascending=False).to_frame()
Ci-dessous, vous verrez les “n-grammes” les plus populaires de BBC News.
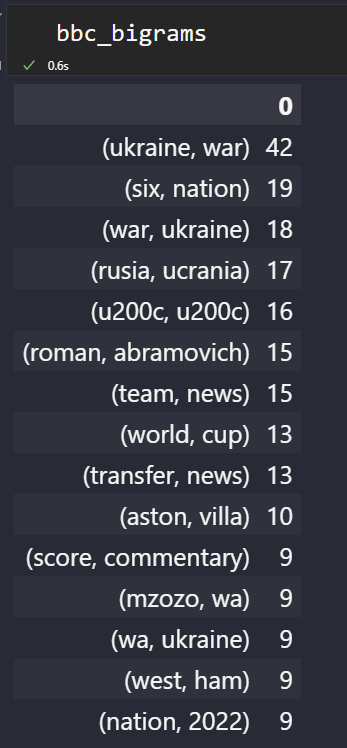 Trame de données NGrams de la BBC
Trame de données NGrams de la BBCPour visualiser simplement les n-grammes les plus populaires d’une source d’information, utilisez le bloc de code ci-dessous.
bbc_bigrams.plot.barh(color="red", width=.8,figsize=(10 , 7))
“Ukraine, guerre” est l’actualité tendance.
Vous pouvez également filtrer les n-grammes pour “Ukraine” et créer une paire “entité-attribut”.
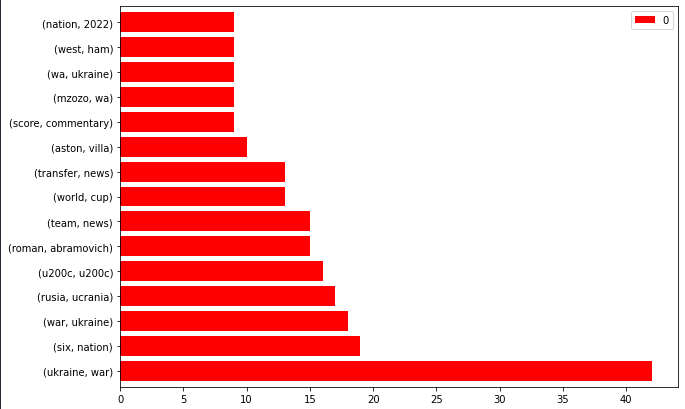 Actualités Plan du site NGrams de la BBC
Actualités Plan du site NGrams de la BBCL’exploration de ces URL et la reconnaissance des “entités de type personne” peuvent vous donner une idée de la façon dont la BBC aborde les situations dignes d’intérêt.
Mais cela va au-delà des “sitemaps d’actualités”. Ainsi, c’est pour un autre jour.
Pour visualiser les n-grammes populaires à partir des plans de site de la source d’actualités, vous pouvez créer une fonction python personnalisée comme ci-dessous.
def ngram_visualize(dataframe:pd.DataFrame, color:str="blue") -> pd.DataFrame.plot:
dataframe.plot.barh(color=color, width=.8,figsize=(10 ,7))
ngram_visualize(ngram_extractor(df_dailymail))
Le résultat est ci-dessous.
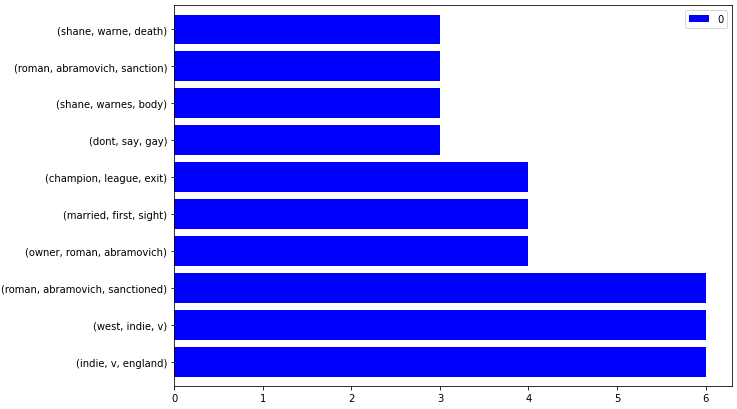 Actualités Plan du site Visualisation du trigramme
Actualités Plan du site Visualisation du trigrammePour le rendre interactif, ajoutez un paramètre supplémentaire comme ci-dessous.
def ngram_visualize(dataframe:pd.DataFrame, backend:str, color:str="blue", ) -> pd.DataFrame.plot:
if backend=="plotly":
pd.options.plotting.backend=backend
return dataframe.plot.bar()
else:
return dataframe.plot.barh(color=color, width=.8,figsize=(10 ,7))
ngram_visualize(ngram_extractor(df_dailymail), backend="plotly")
Comme exemple rapide, vérifiez ci-dessous.
8. Créez vos propres fonctions personnalisées pour analyser les plans de site des sources d’actualités
Lorsque vous auditez à plusieurs reprises les sitemaps d’actualités, vous aurez besoin d’un petit package Python.
Ci-dessous, vous pouvez trouver quatre chaînes de fonctions Python rapides différentes qui utilisent chaque fonction précédente comme rappel.
Pour nettoyer un élément de contenu textuel, utilisez la fonction ci-dessous.
def text_clean(content):
lemmetizer = nltk.stem.WordNetLemmatizer()
stopwords = nltk.corpus.stopwords.words('english')
content = (unicodedata.normalize('NFKD', content)
.encode('ascii', 'ignore')
.decode('utf-8', 'ignore')
.lower())
words = re.sub(r'[^ws]', '', content).split()
return [lemmetizer.lemmatize(word) for word in words if word not in stopwords]
Pour extraire les n-grammes des titres d’actualités du sitemap d’un site Web d’actualités spécifique, utilisez la fonction ci-dessous.
def ngram_extractor(dataframe:pd.DataFrame|pd.Series):
if "news_title" in dataframe.columns:
return dataframe_ngram_extractor(dataframe, ngram=3, first=10)
Utilisez la fonction ci-dessous pour transformer les n-grammes extraits en une trame de données.
def dataframe_ngram_extractor(dataframe:pd.DataFrame|pd.Series, ngram:int, first:int):
raw_words = text_clean(''.join(str(dataframe['news_title'].tolist())))
return (pd.Series(ngrams(raw_words, n = ngram)).value_counts())[:first].sort_values(ascending=False).to_frame()
Pour extraire les sitemaps de plusieurs sites Web d’actualités, utilisez la fonction ci-dessous.
def ngram_df_constructor(df_1:pd.DataFrame, df_2:pd.DataFrame):
df_1_bigrams = dataframe_ngram_extractor(df_1, ngram=2, first=500)
df_1_trigrams = dataframe_ngram_extractor(df_1, ngram=3, first=500)
df_2_bigrams = dataframe_ngram_extractor(df_2, ngram=2, first=500)
df_2_trigrams = dataframe_ngram_extractor(df_2, ngram=3, first=500)
ngrams_df = {
"df_1_bigrams":df_1_bigrams.index,
"df_1_trigrams": df_1_trigrams.index,
"df_2_bigrams":df_2_bigrams.index,
"df_2_trigrams": df_2_trigrams.index,
}
dict_df = (pd.DataFrame({ key:pd.Series(value) for key, value in ngrams_df.items() }).reset_index(drop=True)
.rename(columns={"df_1_bigrams":adv.url_to_df(df_1["loc"])["netloc"][1].split("www.")[1].split(".")[0] + "_bigrams",
"df_1_trigrams":adv.url_to_df(df_1["loc"])["netloc"][1].split("www.")[1].split(".")[0] + "_trigrams",
"df_2_bigrams": adv.url_to_df(df_2["loc"])["netloc"][1].split("www.")[1].split(".")[0] + "_bigrams",
"df_2_trigrams": adv.url_to_df(df_2["loc"])["netloc"][1].split("www.")[1].split(".")[0] + "_trigrams"}))
return dict_df
Ci-dessous, vous pouvez voir un exemple de cas d’utilisation.
ngram_df_constructor(df_bbc, df_guardian)
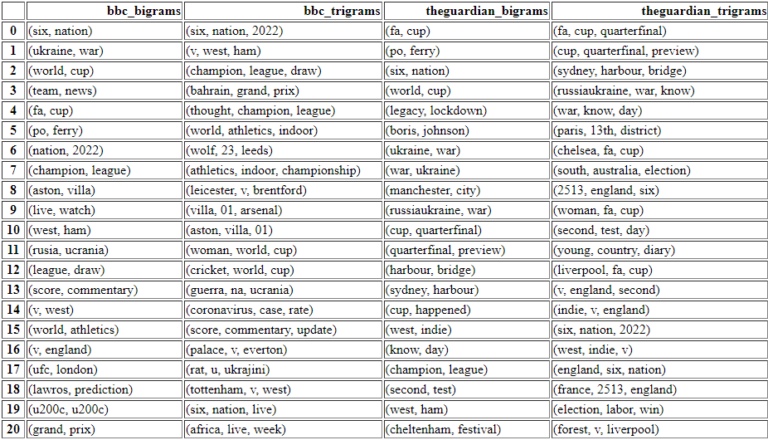 Comparaison populaire de Ngram pour voir l’orientation des sites Web d’actualités.
Comparaison populaire de Ngram pour voir l’orientation des sites Web d’actualités.Ce n’est qu’avec ces quatre fonctions python personnalisées imbriquées que vous pouvez faire les choses ci-dessous.
- Facilement, vous pouvez visualiser ces n-grammes et le site d’actualités compte à vérifier.
- Vous pouvez voir l’orientation des sites Web d’actualités pour le même sujet ou des sujets différents.
- Vous pouvez comparer leur formulation ou le vocabulaire pour les mêmes sujets.
- Vous pouvez voir combien de sous-sujets différents des mêmes sujets ou entités sont traités de manière comparative.
Je n’ai pas mis les chiffres pour les fréquences des n-grammes.
Mais les premiers classés sont les plus populaires de cette source d’information spécifique.
Pour examiner les 500 lignes suivantes, cliquez ici.
9. Extrayez les mots-clés d’actualités les plus utilisés à partir des plans de site d’actualités
En ce qui concerne les mots-clés d’actualité, ils sont étonnamment toujours actifs sur Google.
Par exemple, Microsoft Bing et Google ne pensent plus que les “méta-mots clés” sont un signal utile, contrairement à Yandex.
Cependant, les mots-clés d’actualités des plans de site d’actualités sont toujours utilisés.
Parmi toutes ces sources d’information, seul The Guardian utilise les mots-clés de l’actualité.
Et comprendre comment ils utilisent les mots-clés d’actualité pour fournir de la pertinence est utile.
df_guardian["news_keywords"].str.split().explode().value_counts().to_frame().rename(columns={"news_keywords":"news_keyword_occurence"})
Vous pouvez voir les mots les plus utilisés dans les mots-clés de nouvelles pour The Guardian.
news_keyword_occurence |
|
|---|---|
news, |
250 |
World |
142 |
and |
142 |
Ukraine, |
127 |
UK |
116 |
... |
... |
Cumberbatch, |
1 |
Dune |
1 |
Saracens |
1 |
Pearson, |
1 |
Thailand |
1 |
1409 rows × 1 column
La visualisation est ci-dessous.
(df_guardian["news_keywords"].str.split().explode().value_counts()
.to_frame().rename(columns={"news_keywords":"news_keyword_occurence"})
.head(25).plot.barh(figsize=(10,8),
title="The Guardian Most Used Words in News Keywords", xlabel="News Keywords",
legend=False, ylabel="Count of News Keyword"))
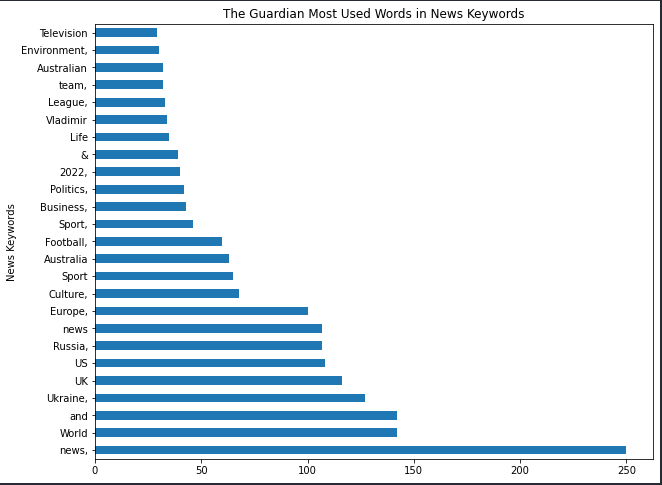 Mots les plus populaires dans les actualités
Mots les plus populaires dans les actualitésLe “,” à la fin des mots-clés de nouvelles indique s’il s’agit d’une valeur distincte ou d’une partie d’une autre.
Je vous suggère de ne pas supprimer les « ponctuations » ou les « mots vides » des mots-clés d’actualités afin que vous puissiez mieux voir leur style d’utilisation des mots-clés d’actualités.
Pour une analyse différente, vous pouvez utiliser “,” comme séparateur.
df_guardian["news_keywords"].str.split(",").explode().value_counts().to_frame().rename(columns={"news_keywords":"news_keyword_occurence"})
La différence de résultat est ci-dessous.
news_keyword_occurence |
|
|---|---|
World news |
134 |
Europe |
116 |
UK news |
111 |
Sport |
109 |
Russia |
90 |
... |
... |
Women's shoes |
1 |
Men's shoes |
1 |
Body image |
1 |
Kae Tempest |
1 |
Thailand |
1 |
1080 rows × 1 column
Concentrez-vous sur le “split (“,”)”.
(df_guardian["news_keywords"].str.split(",").explode().value_counts()
.to_frame().rename(columns={"news_keywords":"news_keyword_occurence"})
.head(25).plot.barh(figsize=(10,8),
title="The Guardian Most Used Words in News Keywords", xlabel="News Keywords",
legend=False, ylabel="Count of News Keyword"))
Vous pouvez voir la différence de résultat pour la visualisation ci-dessous.
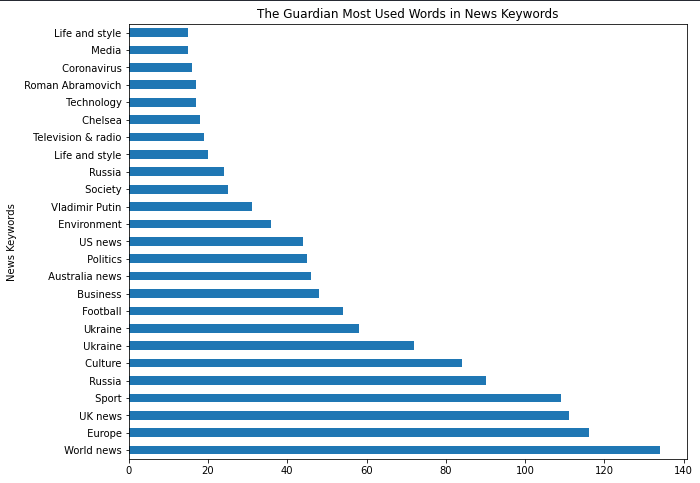 Mots-clés les plus populaires des plans Sitemap pour les actualités
Mots-clés les plus populaires des plans Sitemap pour les actualitésDe « Chelsea » à « Vladamir Poutine » ou « Guerre d’Ukraine » et « Roman Abramovich », la plupart de ces phrases correspondent aux premiers jours de l’invasion de l’Ukraine par la Russie.
Utilisez le bloc de code ci-dessous pour visualiser de manière interactive les mots-clés d’actualités de deux plans de site Web d’actualités différents.
df_1 = df_guardian["news_keywords"].str.split(",").explode().value_counts().to_frame().rename(columns={"news_keywords":"news_keyword_occurence"})
df_2 = df_nyt["news_keywords"].str.split(",").explode().value_counts().to_frame().rename(columns={"news_keywords":"news_keyword_occurence"})
fig = make_subplots(rows = 1, cols = 2)
fig.add_trace(
go.Bar(y = df_1["news_keyword_occurence"][:6].index, x = df_1["news_keyword_occurence"], orientation="h", name="The Guardian News Keywords"), row=1, col=2
)
fig.add_trace(
go.Bar(y = df_2["news_keyword_occurence"][:6].index, x = df_2["news_keyword_occurence"], orientation="h", name="New York Times News Keywords"), row=1, col=1
)
fig.update_layout(height = 800, width = 1200, title_text="Side by Side Popular News Keywords")
fig.show()
fig.write_html("news_keywords.html")
Vous pouvez voir le résultat ci-dessous.
Pour interagir avec le graphique en direct, cliquez ici.
Dans la section suivante, vous trouverez deux échantillons de sous-parcelles différents pour comparer les n-grammes des sites Web d’actualités.
10. Créer des sous-parcelles pour comparer les sources d’informations
Utilisez le bloc de code ci-dessous pour placer les n-grammes les plus populaires des sources d’actualités à partir des titres d’actualités dans une sous-intrigue.
import matplotlib.pyplot as plt
import pandas as pd
df1 = ngram_extractor(df_bbc)
df2 = ngram_extractor(df_skynews)
df3 = ngram_extractor(df_dailymail)
df4 = ngram_extractor(df_guardian)
df5 = ngram_extractor(df_nyt)
df6 = ngram_extractor(df_cnn)
nrow=3
ncol=2
df_list = [df1 ,df2, df3, df4, df5, df6] #df6
titles = ["BBC News Trigrams", "Skynews Trigrams", "Dailymail Trigrams", "The Guardian Trigrams", "New York Times Trigrams", "CNN News Ngrams"]
fig, axes = plt.subplots(nrow, ncol, figsize=(25,32))
count=0
i = 0
for r in range(nrow):
for c in range(ncol):
(df_list[count].plot.barh(ax = axes[r,c],
figsize = (40, 28),
title = titles[i],
fontsize = 10,
legend = False,
xlabel = "Trigrams",
ylabel = "Count"))
count+=1
i += 1
Vous pouvez voir le résultat ci-dessous.
 Les NGrams les plus populaires des sources d’information
Les NGrams les plus populaires des sources d’informationL’exemple de visualisation de données ci-dessus est entièrement statique et ne fournit aucune interactivité.
Dernièrement, Elias Dabbas, créateur d’Advertools, a partagé un nouveau script pour prendre le nombre d’articles, les n-grammes et leur nombre à partir des sources d’information.
Vérifiez ici pour un meilleur tableau de bord de données, plus détaillé et interactif.
L’exemple ci-dessus provient d’Elias Dabbas, et il montre comment prendre le nombre total d’articles, les mots les plus fréquents et les n-grammes des sites Web d’actualités de manière interactive.
Réflexions finales sur l’analyse du sitemap des actualités avec Python
Ce didacticiel a été conçu pour fournir une session éducative de codage Python pour prendre les mots-clés, les n-grammes, les modèles de phrases, les langues et d’autres types d’informations liées au référencement à partir de sites Web d’actualités.
Le référencement des actualités repose fortement sur des réflexes rapides et une création d’articles toujours active.
Le suivi des angles et des méthodes de vos concurrents pour couvrir un sujet montre comment les concurrents ont des réflexes rapides pour les tendances de recherche.
Créer un Google Trends Dashboard et News Source Ngram Tracker pour une analyse SEO comparative et complémentaire de l’actualité serait mieux.
Dans cet article, de temps en temps, j’ai mis des fonctions personnalisées ou des boucles for avancées, et parfois, j’ai gardé les choses simples.
Les praticiens Python débutants à avancés peuvent en bénéficier pour améliorer leurs méthodologies de suivi, de rapport et d’analyse pour le référencement des actualités et au-delà.
Davantage de ressources:
Image en vedette : BestForBest/Shutterstock